МОСКВА, 25 апр — РИА Новости, Татьяна Пичугина. Ровно 65 лет назад британские ученые Джеймс Уотсон и Фрэнсис Крик опубликовали статью о расшифровке структуры ДНК, заложив основы новой науки — молекулярной биологии. Это открытие изменило очень многое в жизни человечества. РИА Новости рассказывает о свойствах молекулы ДНК и о том, почему она так важна.
Во второй половине XIX века биология была совсем молодой наукой. Ученые только приступали к исследованию клетки, а представления о наследственности, хотя и были уже сформулированы Грегором Менделем, не получили широкого признания.
Весной 1868 года молодой швейцарский врач Фридрих Мишер приехал в Университет города Тюбингена (Германия), чтобы заняться научной работой. Он намеревался узнать, из каких веществ состоит клетка. Для экспериментов выбрал лейкоциты, которые легко получить из гноя.
Отделяя ядро от протоплазмы, белков и жиров, Мишер обнаружил соединение с большим содержанием фосфора. Он назвал эту молекулу нуклеином ("нуклеус" на латыни — ядро).
Это соединение проявляло кислотные свойства, поэтому возник термин "нуклеиновая кислота". Его приставка "дезоксирибо" означает, что молекула содержит H-группы и сахара. Потом выяснилось, что на самом деле это соль, но название менять не стали.
В начале XX века ученые уже знали, что нуклеин представляет собой полимер (то есть очень длинную гибкую молекулу из повторяющихся звеньев), звенья сложены четырьмя азотистыми основаниями (аденином, тимином, гуанином и цитозином), а нуклеин содержится в хромосомах — компактных структурах, которые возникают в делящихся клетках. Их способность передавать наследственные признаки продемонстрировал американский генетик Томас Морган в опытах на дрозофилах.
Модель, объяснившая гены
А вот что делает в ядре клетки дезоксирибонуклеиновая кислота, сокращенно ДНК, долго не понимали. Считалось, что она играет какую-то структурную роль в хромосомах. Единицам наследственности — генам — приписывали белковую природу. Прорыв совершил американский исследователь Освальд Эвери, опытным путем доказавший, что генетический материал передается от бактерии к бактерии посредством ДНК.
Стало ясно, что ДНК нужно изучать. Но как? В то время ученым был доступен только рентген. Чтобы просвечивать им биологические молекулы, их приходилось кристаллизовать, а это сложно. Расшифровкой структуры белковых молекул по рентгенограммам занимались в Кавендишской лаборатории (Кембридж, Великобритания). Работавшие там молодые исследователи Джеймс Уотсон и Френсис Крик не располагали собственными экспериментальными данными по ДНК, поэтому они воспользовались рентгенограммами коллег из Королевского колледжа Мориса Уилкинса и Розалинды Франклин.
Уотсон и Крик предложили модель структуры ДНК, точно соответствующую рентгенограммам: две параллельные цепочки закручены в правую спираль. Каждая цепочка складывается произвольным набором азотистых оснований, нанизанных на остов их сахаров и фосфатов, и удерживается водородными связями, протянутыми между основаниями. Причем аденин соединяется только с тимином, а гуанин — с цитозином. Это правило называют принципом комплементарности.
Модель Уотсона и Крика объясняла четыре главных функции ДНК: репликацию генетического материала, его специфику, хранение информации в молекуле и ее способность мутировать.
Ученые опубликовали свое открытие в журнале Nature 25 апреля 1953 года. Через десять лет им вместе с Морисом Уилкинсом присудили Нобелевскую премию по биологии (Розалинда Франклин скончалась в 1958 году от рака в возрасте 37 лет).
"Теперь, более полувека спустя, можно констатировать, что открытие структуры ДНК сыграло в развитии биологии такую же роль, как в физике — открытие атомного ядра. Выяснение строения атома привело к рождению новой, квантовой физики, а открытие строения ДНК привело к рождению новой, молекулярной биологии", — пишет Максим Франк-Каменецкий, выдающийся генетик, исследователь ДНК, автор книги "Самая главная молекула".
Генетический код
Теперь оставалось узнать, как эта молекула действует. Было известно, что ДНК содержит инструкции для синтеза клеточных белков, которые выполняют всю работу в клетке. Белки — это полимеры, состоящие из повторяющихся наборов (последовательностей) аминокислот. Причем аминокислот — всего двадцать. Виды животных отличаются друг от друга набором белков в клетках, то есть разными последовательностями аминокислот. Генетика утверждала, что эти последовательности задаются генами, которые, как тогда считали, служат первокирпичиками жизни. Но что такое гены, никто в точности не представлял.
Ясность внес автор теории Большого взрыва физик Георгий Гамов, сотрудник Университета Джорджа Вашингтона (США). Основываясь на модели двухцепочечной спирали ДНК Уотсона и Крика, он предположил, что ген — это участок ДНК, то есть некая последовательность звеньев — нуклеотидов. Поскольку каждый нуклеотид — это одно из четырех азотистых оснований, то нужно просто выяснить, как четыре элемента кодируют двадцать. В этом состояла идея генетического кода.
К началу 1960-х установили, что белки синтезируются из аминокислот в рибосомах — своего рода "фабриках" внутри клетки. Чтобы приступить к синтезу белка, к ДНК приближается фермент, распознает определенный участок в начале гена, синтезирует копию гена в виде маленькой РНК (ее называют матричной), затем уже в рибосоме из аминокислот выращивается белок.
Выяснили также, что генетический код — трехбуквенный. Это значит, что одной аминокислоте соответствуют три нуклеотида. Единицу кода назвали кодоном. В рибосоме информация с мРНК считывается кодон за кодоном, последовательно. И каждому из них соответствует несколько аминокислот. Как же выглядит шифр?
На этот вопрос ответили Маршалл Ниренберг и Генрих Маттеи из США. В 1961 году они впервые доложили свои результаты на биохимическом конгрессе в Москве. К 1967-му генетический код полностью расшифровали. Он оказался универсальным для всех клеток всех организмов, что имело далеко идущие последствия для науки.
Открытие структуры ДНК и генетического кода полностью переориентировало биологические исследования. То, что у каждого индивида уникальная последовательность ДНК, кардинально изменило криминалистику. Расшифровка генома человека дала антропологам совершенно новый метод изучения эволюции нашего вида. Недавно изобретенный редактор ДНК CRISPR-Cas позволил сильно продвинуть вперед генную инженерию. По всей видимости, в этой молекуле хранится решение и самых злободневных проблем человечества: рака, генетических заболеваний, старения.
Министерство образования российской федерации
Южно-уральский государственный университет
Кафедра «Экономики и Управления»
Дисциплина «Концепция современного естествознания»
«Химические основы строения ДНК»
Выполнил: студент ЭиУ-232
Седракян Игорь
Проверил: Сенин А.В.
Челябинск
Введение
Структура ДНК
Состав ДНК
Макромолекулярная структура ДНК
4.1 Выделение дезоксирибонуклеиновых кислот
4.2 Фракционирование
Функции ДНК
Межнуклеотидные связи
6.1 Межнуклеотидная связь в ДНК
7. Матричный синтез ДНК
7.1 ДНК-полимеразы
7.2 Инициация цепей ДНК
7.3 Расплетение двойной спирали ДНК
7.4Прерывистый синтез ДНК
7.5 Кооперативное действие белков репликационной вилки
8. Заключение
Использованные источники
Введение
Наследуемые признаки заложены в материальных единицах, генах, которые располагаются в хромосомах клеточного ядра. Химическая природа генов известна с 1944 г.: речь идет о дезоксирибонуклеиновой кислоте (ДНК). Физическая структура была выяснена в 1953 г. Двойная спираль этой макромолекулы объясняет механизм наследственной передачи признаков.
Присматриваясь к окружающему нас миру, мы отмечаем великое разнообразие живых существ – от растений до животных. Под этим кажущимся разнообразием в действительности скрывается удивительное единство живых клеток – элементов, из которых собран любой организм и взаимодействием которых определяется его гармоничное существование. С позиции вида сходство между отдельными особями велико, и все-таки не существует двух абсолютно идентичных организмов (не считая однояйцовых близнецов). В конце XIX века в работах Грегора Менделя были сформулированы основные законы, определившие наследственную передачу признаков из поколения в поколение. В начале ХХ века в опытах Т.Моргана было показано, что элементарные наследуемые признаки обусловлены материальными единицами (генами), локализованными в хромосомах, где они располагаются последовательно друг за другом.
В 1944 г. работы Эвери, Мак-Леода и Мак-Карти определили химическую природу генов: они состоят из дезоксирибонуклеиновой кислоты (ДНК). Через 10 лет Дж. Уотсон и Ф. Крик предложили модель физической структуры молекулы ДНК. Длинная молекула образована двойной спиралью, а комплиментарное взаимодействие между двумя нитями этой спирали позволяет понять, каким образом генетическая информация точно копируется (реплицируется) и передается последующим поколениям.
Одновременно с этими открытиями ученые пытались проанализировать и «продукты» генов, т.е. те молекулы, которые синтезируются в клетках под их контролем. Работы Эфрусси, Бидла и Татума накануне второй мировой войны выдвинули идею о том, что гены «продуцируют» белки. Итак, ген хранит информацию для синтеза белка (фермента), необходимого для успешного осуществления в клетке определенной реакции. Но пришлось подождать до 60-х годов, прежде чем был разгадан сложный механизм расшифровки информации, заключенной в ДНК, и ее перевода в форму белка. В конце концов, во многом благодаря трудам Ниренберга (США), был открыт закон соответствия между ДНК и белками – генетический код.
Структура ДНК .
В 1869 году швейцарский биохимик Фридрих Мишер обнаружил в ядре клеток соединения с кислотными свойствами и с еще большей молекулярной массой, чем белки. Альтман назвал их нуклеиновыми кислотами, от латинского слова «нуклеус» - ядро. Так же, как и белки, нуклеиновые кислоты являются полимерами. Мономерами их служат нуклеотиды, в связи с чем нуклеиновые кислоты можно еще назвать полинуклеотидами.
Нуклеиновые кислоты были найдены в клетках всех организмов, начиная от простейших и кончая высшими. Самое удивительное, что химический состав, структура и основные свойства этих веществ оказались сходными у разнообразных живых организмов. Но если в построении белков принимают участие около 20 видов аминокислот, то разных нуклеотидов, входящих в состав нуклеиновых кислот, всего четыре.
Нуклеиновые кислоты различают на две разновидности - дезоксирибонуклеиновую кислоту (ДНК) и рибонуклеиновую кислоту (РНК). В состав ДНК входят азотистые основания (аденин (А), гуанин (Г), тимин (Т), цитозин (Ц)), дезоксирибоза С 5 Н 10 О 4 и остаток фосфорной кислоты. В состав РНК вместо тимина входит урацил (У), а вместо дезоксирибозы - рибоза (С5Н10О5). Мономерами ДНК и РНК являются нуклеотиды, которые состоят из азотистых, пуриновых (аденин и гуанин) и пиримидиновых (урацил, тимин и цитозин) оснований, остатка фосфорной кислоты и углеводов (рибозы и дезоксирибозы).
Молекулы
ДНК содержатся в хромосомах ядра клетки
живых организмов, в эквивалентных
структурах митохондрий, хлоропластов,
в прокариотных клетках и во многих
вирусах. По своей структуре молекула
ДНК похожа на двойную спираль. Структурная
модель ДНК в
виде двойной спирали
впервые предложена в 1953 г. американским
биохимиком Дж. Уотсоном и английским
биофизиком и генетиком Ф. Криком,
удостоенными вместе с английским
биофизиком М. Уилкинсоном, получившим
рентгенограмму ДНК, Нобелевской премии
1962 г. Нуклеиновые кислоты - это биополимеры,
макромолекулы которых состоят из
многократно повторяющихся звеньев -
нуклеотидов. Поэтому их называют также
полинуклеотидами. Важнейшей характеристикой
нуклеиновых кислот является их
нуклеотидный состав. В состав нуклеотида
- структурного звена нуклеиновых кислот
- входят три составные части:
азотистое основание - пиримидиновое или пуриновое. В нуклеиновых кислотах содержатся основания 4-х разных видов: два из них относятся к классу пуринов и два – к классу пиримидинов. Азот, содержащийся в кольцах, придает молекулам основные свойства.
моносахарид - рибоза или 2-дезоксирибоза. Сахар, входящий в состав нуклеотида, содержит пять углеродных атомов, т.е. представляет собой пентозу. В зависимости от вида пентозы, присутствующей в нуклеотиде, различают два вида нуклеиновых кислот – рибонуклеиновые кислоты (РНК), которые содержат рибозу, и дезоксирибонуклеиновые кислоты (ДНК), содержащие дизоксирибозу.
остаток фосфорной кислоты. Нуклеиновые кислоты являются кислотами потому, что в их молекулах содержится фосфорная кислота.
Нуклеотид - фосфорный эфир нуклеозида. В состав нуклеозида входят два компонента: моносахарид (рибоза или дезоксирибоза) и азотистое основание.
Метод определения состава ПК основан на анализе гидролизатов, образующихся при их ферментативном или химическом расщеплении. Обычно используются три способа химического расщепления НК. Кислотный гидролиз в жестких условиях (70%-ная хлорная кислота, 100°С, 1ч или 100%-ная муравьиная кислота, 175 °C, 2 ч), применяемый для анализа как ДНК, так и РНК, приводит к разрыву всех N-гликозидных связей и образованию смеси пуриновых и пиримидиновых оснований.
Нуклеотиды соединяются в цепь посредством ковалентных связей. Образованные таким образом цепи нуклеотидов объединяется в одну молекулу ДНК по всей длине водородными связями: адениновый нуклео-тид одной цепи соединяется с тиминовым нуклеотидом другой цепи, а гуаниновый - с цитозиновым. При этом аденин всегда распознает только тимин и связывается с ним и наоборот. Подобную пару образуют гуанин и цитозин. Такие пары оснований, как и нуклеотиды, называются комплементарными, а сам принцип формирования двухцепочной молекулы ДНК - принципом комплементарности. Число нуклеотидных пар, например, в организме человека составляет 3 - 3,5 млрд.
ДНК - материальный носитель наследственной информации, которая кодируется последовательностью нуклеотидов. Расположение четырех типов нуклеотидов в цепях ДНК определяет последовательность аминокислот в молекулах белка, т.е. их первичную структуру. От набора белков зависят свойства клеток и индивидуальные признаки организмов. Определенное сочетание нуклеотидов, несущих информацию о структуре белка, и последовательность их расположения в молекуле ДНК образуют генетический код. Ген (от греч. genos - род, происхождение) - единица наследственного материала, ответственная за формирование какого-либо признака. Он занимает участок молекулы ДНК, определяющий структуру одной молекулы белка. Совокупность генов, содержащихся в одинарном наборе хромосом данного организма, называется геномом, а генетическая конституция организма (совокупность всех его генов) - генотипом. Нарушение последовательности нуклеотидов в цепи ДНК, а следовательно, в генотипе приводит к наследственным изменениям в организме-мутациям.
Для молекул ДНК характерно важное свойство удвоения - образования двух одинаковых двойных спиралей, каждая из которых идентична исходной молекуле. Такой процесс удвоения молекулы ДНК называется репликацией. Репликация включает в себя разрыв старых и формирование новых водородных связей, объединяющих цепи нуклеотидов. В начале репликации две старые цепи начинают раскручиваться и отделяться друг от друга. Затем по принципу комплементарности к двум старым цепям пристраиваются новые. Так образуются две идентичные двойные спирали. Репликация обеспечивает точное копирование генетической информации, заключенной в молекулах ДНК, и передает ее по наследству от поколения к поколению.
Состав ДНК
ДНК (дезоксирибонуклеиновая кислота) - биологический полимер, состоящий из двух полинуклеотидных цепей, соединенных друг с другом. Мономеры, составляющие каждую из цепей ДНК, представляют собой сложные органические соединения, включающие одно из четырех азотистых оснований: аденин (А) или тимин (Т), цитозин (Ц) или гуанин (Г); пятиатомный сахар пентозу - дезоксирибозу, по имени которой получила название и сама ДНК, а также остаток фосфорной кислоты. Эти соединения носят название нуклеотидов. В каждой цепи нуклеотиды соединяются путем образования ковалентных связей между дезоксирибозой одного и остатком фосфорной кислоты последующего нуклеотида. Объединяются две цепи в одну молекулу при помощи водородных связей, возникающих между азотистыми основаниями, входящими в состав нуклеотидов, образующих разные цепи.
Исследуя нуклеотидный состав ДНК различного происхождения, Чаргафф обнаружил следующие закономерности.
1. Все ДНК независимо от их происхождения содержат одинаковое число пуриновых и пиримидиновых оснований. Следовательно, в любой ДНК на каждый пуриновый нуклеотид приходится один пиримидиновый.
2. Любая ДНК всегда содержит в равных количествах попарно аденин и тимин, гуанин и цитозин, что обычно обозначают как А=Т и G=C. Из этих закономерностей вытекает третья.
3. Количество оснований, содержащих аминогруппы в положении 4 пиримидинового ядра и 6 пуринового (цитозин и аденин), равно количеству оснований, содержащих оксо-группу в тех же положениях (гуанин и тимин), т. е. A+C=G+T. Эти закономерности получили название правил Чаргаффа. Наряду с этим было установлено, что для каждого типа ДНК суммарное содержание гуанина и цитозина не равно суммарному содержанию аденина и тимина, т. е. что (G+C)/(A+T), как правило, отличается от единицы (может быть как больше, так и меньше ее). По этому признаку различают два основных типа ДНК: АТ-тип с преимущественным содержанием аденина и тимина и GC-тип с преимущественным содержанием гуанина и цитозина.
Величину отношения содержания суммы гуанина и цитозина к сумме содержания аденина и тимина, характеризующую нуклеотидный состав данного вида ДНК, принято называть коэффициентом специфичности . Каждая ДНК имеет характерный коэффициент специфичности, который может изменяться в пределах от 0,3 до 2,8. При подсчете коэффициента специфичности учитывается содержание минорных оснований, а также замены основных оснований их производными. Например, при подсчете коэффициента специфичности для ЭДНК зародышей пшеницы, в которой содержится 6% 5-метилцитозина, последний входит в сумму содержания гуанина (22,7%) и цитозина (16,8%). Смысл правил Чаргаффа для ДНК стал понятным после установления ее пространственной структуры.
Открытие генетической роли ДНК
ДНК была открыта Иоганном Фридрихом Мишером в 1869 году. Из остатков клеток, содержащихся в гное, он выделил вещество, в состав которого входят азот и фосфор. Впервые нуклеиновую кислоту, свободную от белков, получил Р. Альтман в 1889 г., который и ввел этот термин в биохимию. Лишь к середине 1930-х годов было доказано, что ДНК и РНК содержатся в каждой живой клетке. Первостепенная роль в утверждении этого фундаментального положения принадлежит А. Н. Белозерскому, впервые выделившему ДНК из растений. Постепенно было доказано, что именно ДНК, а не белки, как считалось раньше, является носителем генетической информации. О. Эверину, Колину Мак-Леоду и Маклину Мак-Карти (1944 г.) удалось показать, что за так называемую трансформацию (приобретение болезнетворных свойств безвредной культурой в результате добавления в неё мёртвых болезнетворных бактерий) отвечают выделенные из пневмококков ДНК. Эксперимент американских учёных (эксперимент Херши - Чейз, 1952 г.) с помеченными радиоактивными изотопами белками и ДНК бактериофагов показали, что в заражённую клетку передаётся только нуклеиновая кислота фага, а новое поколение фага содержит такие же белки и нуклеиновую кислоту, как исходный фаг.Вплоть до 50-х годов XX века точное строение ДНК, как и способ передачи наследственной информации, оставалось неизвестным. Хотя и было доподлинно известно, что ДНК состоит из нескольких цепочек, состоящих из нуклеотидов, никто не знал точно, сколько этих цепочек и как они соединены.Структура двойной спирали ДНК была предложена Френсисом Криком и Джеймсом Уотсоном в 1953 году на основании рентгеноструктурных данных, полученных Морисом Уилкинсом и Розалинд Франклин, и «правил Чаргаффа», согласно которым в каждой молекуле ДНК соблюдаются строгие соотношения, связывающие между собой количество азотистых оснований разных типов. Позже предложенная Уотсоном и Криком модель строения ДНК была доказана, а их работа отмечена Нобелевской премией по физиологии или медицине 1962 г. Среди лауреатов не было скончавшейся к тому времени Розалинды Франклин, так как премия не присуждается посмертно.В 1960 г. сразу в нескольких лабораториях был открыт фермент РНК-полимераза, осуществляющий синтез РНК на ДНК-матрицах. Генетический аминокислотный код был полностью расшифрован в 1961–1966 гг. усилиями лабораторий М. Ниренберга, С. Очоа и Г. Кораны.
Химический состав и структурная организация молекулы днк.
ДНК - дезоксирибонуклеиновая кислота. Молекула ДНК – это самый крупный биополимер, мономером которого является нуклеотид. Нуклеотид состоит из остатков 3 веществ: 1 – азотистого основания; 2 – углевода дезоксирибозы; 3 - фосфорной кислоты (рисунок – строение нуклеотида). Нуклеотиды, участвующие в образовании молекулы ДНК отличаются друг от друга азотистыми основаниями. Азотистые основание: 1 – Цитозин и Тимин (производные пиримидина) и 2 – Аденин и Гуанин (производные пурина). Соединение нуклеотидов в нити ДНК происходит через углевод одного нуклеотида и остаток фосфорный кислоты соседнего (рисунок – строение полинуклеотидной цепи). Правило Чаргаффа (1951г.): число пуриновых оснований в ДНК всегда равно числу пиримидиновых, А=Т Г=Ц.
1953г. Дж. Уотсон и Ф. Крик – Представили модель строения молекулы ДНК (рисунок – строение молекулы ДНК).
Первичная структура – последовательность расположения мономерных звеньев (мононуклеотидов) в линейных полимерах. Цепь стабилизируется 3,5 – фосфодиэфирными связями.Вторичная структура – двойная спираль, формирование которой определяется межнуклеотидными водородными связями, которые образуются между основаниями входящими в канонические пары А-Т (2 водородные связи) и Г-Ц (3 водородные связи). Цепи удерживаются стекинг-взаимодействиями, электростатическими взаимодействиями,Ван-Дер-Ваальсовыми взаимодействиями.Третичная структура – общая форма молекул биополимеров. Сверхспиральная структура – когда замкнутая двойная спираль образует не кольцо, а структуру с витками более высокого порядка (обеспечивает компактность).Четвертичная структура – укладка молекул в полимолекулярные ансамбли. Для нуклеиновых кислот - это ансамбли, включающие молекулы белков.
По своему химическому строению ДНК (дезоксирибонуклеиновая кислота ) является биополимером , мономерами которого являются нуклеотиды . То есть ДНК - это полинуклеотид . Причем молекула ДНК обычно состоит из двух цепей, закрученных друг относительно друга по винтовой линии (часто говорят «спирально закрученных») и соединенных между собой водородными связями.
Цепочки могут быть закручены как в левую, так и в правую (чаще всего) сторону.
У некоторых вирусов ДНК состоит из одной цепи.
Каждый нуклеотид ДНК состоит из 1) азотистого основания, 2) дезоксирибозы, 3) остатка фосфорной кислоты.
Двойная правозакрученная спираль ДНК
В состав ДНК входят следующие: аденин , гуанин , тимин и цитозин . Аденин и гуанин относятся к пуринам , а тимин и цитозин - к пиримидинам . Иногда в состав ДНК входит урацил, который обычно характерен для РНК , где замещает тимин.
Азотистые основания одной цепи молекулы ДНК соединяются с азотистыми основаниями другой строго по принципу комплементарности: аденин только с тимином (образуют между собой две водородные связи), а гуанин только с цитозином (три связи).
Азотистое основание в самом нуклеотиде соединено с первым атомом углерода циклической формы дезоксирибозы , которая является пентозой (углеводом с пятью атомами углерода). Связь является ковалентной, гликозидной (C-N). В отличие от рибозы у дезоксирибозы отсутствует одна из гидроксильных групп. Кольцо дезоксирибозы формируют четыре атома углерода и один атом кислорода. Пятый атом углерода находится вне кольца и соединен через атом кислорода с остатком фосфорной кислоты. Также через атом кислорода у третьего атома углерода присоединяется остаток фосфорной кислоты соседнего нуклеотида.
Таким образом, в одной цепи ДНК соседние нуклеотиды связаны между собой ковалентными связями между дезоксирибозой и фосфорной кислотой (фосфодиэфирная связь). Образуется фосфат-дезоксирибозный остов. Перпендикулярно ему, навстречу другой цепочке ДНК, направлены азотистые основания, которые соединяются с основаниями второй цепочки водородными связями.
Строение ДНК таково, что остовы соединенных водородными связями цепочек направлены в разные стороны (говорят «разнонаправлены», «антипараллельны»). С той стороны, где одна заканчивается фосфорной кислотой, соединенной с пятым атомом углерода дезоксирибозы, другая заканчивается «свободным» третьим атомом углерода. То есть остов одной цепочки перевернут как бы с ног на голову относительно другой. Таким образом, в строении цепочек ДНК различают 5"-концы и 3"-концы.
При репликации (удвоении) ДНК синтез новых цепочек всегда идет от их 5-го конца к третьему, так как новые нуклеотиды могут присоединяться только к свободному третьему концу.
В конечном итоге (опосредованно через РНК) каждые идущие подряд три нуклеотида в цепи ДНК кодируют одну аминокислоту белка.
Открытие строения молекулы ДНК произошло в 1953 году благодаря работам Ф. Крика и Д. Уотсона (чему также способствовали ранние работы других ученых). Хотя как химическое вещество ДНК было известно еще в XIX веке. В 40-х годах XX века стало ясно, что именно ДНК является носителем генетической информации.
Двойная спираль считается вторичной структурой молекулы ДНК. У клетках эукариот подавляющее количество ДНК находится в хромосомах , где связана с белками и другими веществами, а также подвергается более плотной упаковке.
DNA Logic - это технология ДНК-вычислений, которая сегодня находится в зачаточном состоянии, однако в будущем на нее возлагаются большие надежды. Биологические нанокомпьютеры, вживляемые в живые организмы, пока видятся нам как нечто фантастическое, нереальное. Но то, что нереально сегодня, уже завтра может оказаться чем-то обыденным и настолько естественным, что трудно будет представить, как без этого можно было обходиться в прошлом.
Итак, ДНК-вычисления - это раздел области молекулярных вычислений на границе молекулярной биологии и компьютерных наук. Основная идея ДНК-вычислений - построение новой парадигмы, создание новых алгоритмов вычислений на основе знаний о строении и функциях молекулы ДНК и операций, которые выполняются в живых клетках над молекулами ДНК при помощи различных ферментов. К перспективам ДНК-вычислений относится создание биологического нанокомпьютера, который будет способен хранить терабайты информации при объеме в несколько микрометров. Такой компьютер можно будет вживлять в клетку живого организма, а его производительность будет исчисляться миллиардами операций в секунду при энергопотреблении не более одной миллиардной доли ватта.
Преимущества ДНК в компьютерных технологиях
Для современных процессоров и микросхем в качестве строительного материала используется кремний. Но возможности кремния не беспредельны, и в конечном счете мы подойдем к той черте, когда дальнейший рост вычислительной мощности процессоров окажется исчерпан. А потому перед человечеством уже сейчас остро стоит проблема поиска новых технологий и материалов, которые смогли бы в будущем заменить кремний.
Молекулы ДНК могут оказаться тем самым материалом, который впоследствии заменит кремниевые транзисторы с их бинарной логикой. Достаточно сказать, что всего один фунт (453 г) ДНК-молекул обладает емкостью для хранения данных, которая превосходит суммарную емкость всех современных электронных систем хранения данных, а вычислительная мощность ДНК-процессора размером с каплю будет выше самого мощного современного суперкомпьютера.
Более 10 триллионов ДНК-молекул занимают объем всего в 1 см3. Однако такого количества молекул достаточно для хранения объема информации в 10 Тбайт, при этом они могут производить 10 трлн операций в секунду.
Еще одно преимущество ДНК-процессоров в сравнении с обычными кремниевыми процессорами заключается в том, что они могут производить все вычисления не последовательно, а параллельно, что обеспечивает выполнение сложнейших математических расчетов буквально за считаные минуты. Традиционным компьютерам для выполнения таких расчетов потребовались бы месяцы и годы.
Строение молекул ДНК
Как известно, современные компьютеры работают с бинарной логикой, подразумевающей наличие всего двух состояний: логического нуля и единицы. Используя двоичный код, то есть последовательность нулей и единиц, можно закодировать любую информацию. В молекулах ДНК имеется четыре базовых основания: аденин (A), гуанин (G), цитозин (C) и тимин (T), связанных друг с другом в цепочку. То есть молекула ДНК (одинарная цепочка) может иметь, например, такой вид: ATTTACGGCC - здесь используется не двоичная, а четверичная логика. И подобно тому, как в двоичной логике любую информацию можно закодировать в виде последовательности нулей и единиц, в молекулах ДНК можно кодировать любую информацию путем сочетания базовых оснований.
Базовые основания в молекулах ДНК находятся друг от друга на расстоянии 0,34 нанометра, что обусловливает их огромную информативную емкость - линейная плотность составляет 18 Мбит/дюйм. Если же говорить о поверхностной информативной плотности, предполагая, что на одно базовое основание приходится площадь в 1 квадратный нанометр, то она составляет более миллиона гигабит на квадратный дюйм. Для сравнения отметим, что поверхностная плотность записи современных жестких дисков составляет порядка 7 Гбит/дюйм 2.
Другое важное свойство ДНК-молекул заключается в том, что они могут иметь форму регулярной двойной спирали, диаметр которой составляет всего 2 нм. Такая спираль состоит из двух цепей (последовательностей базовых оснований), причем содержание первой цепи строго соответствует содержанию второй.
Это соответствие достигается благодаря наличию водородных связей между направленными навстречу друг другу основаниями двух цепей - попарно G и C или A и T. Описывая это свойство двойной спирали, молекулярные биологи говорят, что цепи ДНК комплементарны за счет образования пар G-C и A-T.
К примеру, если последовательность S записывается как ATTACGTCG, то дополняющая ее последовательность S’ будет иметь вид TAATGCAGC.
Процесс соединения двух одинарных цепочек ДНК путем связывания комплементарных оснований в регулярную двойную спираль называется ренатурацией, а обратный процесс, то есть разъединение двойной цепочки и получение двух одинарных цепочек, - денатурацией (рис. 1).
Рис. 1. Процессы ренатурации и денатурации
Комплементарная особенность строения ДНК-молекул может использоваться при ДНК-вычислениях. К примеру, на основе дополняющих друг друга последовательностей можно реализовать мощнейший механизм коррекции ошибок, который чем-то напоминает технологию зеркалирования данных RAID Level 1.
Базовые операции над ДНК-молекулами
Для различных манипуляций над ДНК-молекулами используются различные энзимы (ферменты). И точно так же, как современные микропроцессоры имеют набор базовых операций типа сложения, сдвига, логических операций AND, OR и NOT NOR, ДНК-молекулы под воздействием энзимов могут выполнять такие базовые операции, как разрезание, копирование, вставка и др. Причем все операции над ДНК-молекулами можно производить параллельно и независимо от других операций, к примеру дополнение цепочки ДНК осуществляется при воздействии на исходную молекулу ферментов - полимераз. Для работы полимеразы необходимо наличие одноцепочечной молекулы (матрицы), определяющей добавляемую цепочку по принципу комплементарности, праймера (небольшого двухцепочечного участка) и свободных нуклеотидов в растворе. Процесс дополнения цепочки ДНК показан на рис. 2.
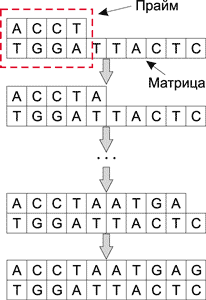
Рис. 2. Процесс дополнения цепочки ДНК
при воздействии на исходную молекулу полимеразы
Существуют полимеразы, которым не требуются матрицы для удлинения цепочки ДНК. Например, терминальная трансфераза добавляет одинарные цепочки ДНК к обоим концам двухцепочечной молекулы. Таким образом можно конструировать произвольную цепь ДНК (рис. 3).

Рис. 3. Процесс удлинения цепочки ДНК
За укорачивание и разрезание молекул ДНК отвечают ферменты - нуклеазы. Различают эндонуклеазы и экзонуклеазы. Последние могут укорачивать и одноцепочечные и двухцепочечные молекулы с одного или с обоих концов (рис. 4), а эндонуклеазы - только с концов.
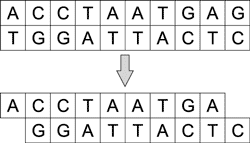
Рис. 4. Процесс укорачивания молекулы
ДНК под воздействием экзонуклеазы
Разрезание молекул ДНК возможно под воздействием сайт-специфичных эндонуклеазов - рестриктазов, которые разрезают их в определенном месте, закодированном последовательностью нуклеотидов (сайтом узнавания). Разрез может быть прямым или несимметричным и проходить по сайту узнавания либо вне его. Эндонуклеазы разрушают внутренние связи в молекуле ДНК (рис. 5).
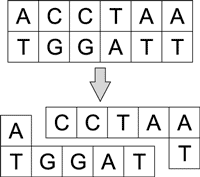
Рис. 5. Разрезание молекулы ДНК
под воздействием рестриктазов
Сшивка - операция, обратная разрезанию, - происходит под воздействием ферментов - лигазов. «Липкие концы» соединяются вместе с образованием водородных связей. Лигазы служат для того, чтобы закрыть насечки, то есть способствовать образованию в нужных местах фосфодиэфирных связей, соединяющих основания друг с другом в пределах одной цепочки (рис. 6).

Рис. 6. Сшивка ДНК-молекул под воздействием лигазов
Еще одна интересная операция над ДНК-молекулами, которую можно отнести к числу базовых, - это модификация. Она используется для того, чтобы рестриктазы не смогли найти определенный сайт и не разрушили молекулу. Существует несколько типов модифицирующих ферментов - метилазы, фосфатазы и т.д.
Метилаза имеет тот же сайт узнавания, что и соответствующая рестриктаза. При нахождении нужной молекулы метилаза модифицирует участок с сайтом так, что рестриктаза уже не сможет идентифицировать эту молекулу.
Копирование, или размножение, ДНК-молекул осуществляется в ходе полимеразной цепной реакции (Polymerase Chain Reaction, PCR) - рис. 7. Процесс копирования можно разделить на несколько стадий: денатурация, праймирование и удлинение. Он происходит лавинообразно. На первом шаге из одной молекулы образуются две, на втором - из двух молекул - четыре, а после n-шагов получается уже 2n молекул.

Рис. 7. Процесс копирования ДНК-молекулы
Еще одна операция, которую можно производить над ДНК-молекулами, - это секвенирование, то есть определение последовательности нуклеотидов в ДНК. Для секвенирования цепочек разной длины применяют различные методы. При помощи метода праймер-опосредованной прогулки удается на одном шаге секвенировать последовательность в 250-350 нуклеотидов. После открытия рестриктаз стало возможным секвенировать длинные последовательности по частям.
Ну и последняя процедура, которую мы упомянем, - это гель-электрофорез, используемый для разделения молекул ДНК по длине. Если молекулы поместить в гель и приложить постоянное электрическое поле, то они будут двигаться по направлению к аноду, причем более короткие молекулы будут двигаться быстрее. Используя данное явление, можно реализовать сортировку ДНК-молекул по длине.
ДНК-вычисления
ДНК-молекулы со своей уникальной формой строения и возможностью реализовать параллельные вычисления позволяют по-другому взглянуть на проблему компьютерных вычислений. Традиционные процессоры выполняют программы последовательно. Несмотря на существование многопроцессорных систем, многоядерных процессоров и различных технологий, направленных на повышение уровня параллелизма, в своей основе все компьютеры, построенные на основе фон-неймановской архитектуры, являются устройствами с последовательным режимом выполнения команд. Все современные процессоры реализуют следующий алгоритм обработки команд и данных: выборка команд и данных из памяти и исполнение инструкций над выбранными данными. Этот цикл повторяется многократно и с огромной скоростью.
ДНК-вычисления имеют в своей основе абсолютно иную, параллельную архитектуру и в ряде случаев именно благодаря этому способны с легкостью рассчитывать те задачи, для решения которых компьютерам на базе фон-неймановской архитектуры потребовались бы годы.
Эксперимент Эдлмана
История ДНК-вычислений начинается в 1994 году. Именно тогда Леонард М. Эдлман (Leonard M. Adleman) попытался решить весьма тривиальную математическую задачу абсолютно нетривиальным способом - с использованием ДНК-вычислений. Фактически это было первой демонстраций прототипа биологического компьютера на основе ДНК-вычислений.
Задача, которую Эдлман выбрал для выполнения с помощью ДНК-вычислений, известна как поиск гамильтонова пути в графе или выбор маршрута путешествия (traveling salesman problem). Смысл ее заключается в следующем: имеется несколько городов, которые необходимо посетить, причем побывать в каждом городе можно только один раз.
Зная пункт отправления и конечный пункт, необходимо определить маршрут путешествия (если он существует). При этом маршрут составляется с учетом возможных авиаперелетов и коннектов различных авиарейсов.
Итак, предположим, что имеется всего четыре города (в эксперименте Эдлмана использовалось семь городов): Атланта (Atlanta), Бостон (Boston), Детройт (Detroit) и Чикаго (Chicago). Перед путешественником ставится задача выбрать маршрут, чтобы попасть из Атланты в Детройт, побывав при этом в каждом городе только один раз. Схемы возможных сообщений между городами показаны на рис. 8.

Рис. 8. Схемы возможных сообщений
между городами
Нетрудно заметить (для этого требуется всего несколько секунд), что единственно возможный маршрут (гамильтонов путь) следующий: Атланта - Бостон - Чикаго - Детройт.
Действительно, при небольшом количестве городов составить такой маршрут довольно просто. Но с увеличением их числа сложность решения задачи экспоненциально возрастает и становится трудновыполнимой не только для человека, но и для компьютера.
Так, на рис. 9 показан граф из семи вершин с указанием возможных переходов между ними. Для поиска гамильтонова пути обычному человеку требуется не более одной минуты. Именно такой граф был использован в эксперименте Эдлмана. На рис. 10 представлен граф из 12 вершин - в этом случае поиск гамильтонова пути оказывается уже не такой простой задачей. Вообще, сложность решения задачи поиска гамильтонова пути возрастает экспоненциально с ростом числа вершин в графе. К примеру, для графа из 10 вершин существует 106 возможных путей; для графа из 20 вершин - 1012, а для графа из 100 вершин - 10100 вариантов. Понятно, что в последнем случае для генерации всех возможных путей и их проверки потребуется огромное время даже для современного суперкомпьютера.

Рис. 9. Поиск оптимального маршрута путешествия

Рис. 10. Граф, состоящий из 12 вершин
Итак, вернемся к нашему примеру с поиском гамильтонова пути в случае четырех городов (см. рис. 8).
Для решения данной задачи с использованием ДНК-вычислений Эдлман закодировал название каждого города в виде одной цепочки ДНК, причем каждая из них содержала 20 базовых оснований. Для простоты мы будем кодировать каждый город ДНК-цепочкой из восьми оснований. ДНК-коды городов показаны в табл. 1. Обратите внимание, что цепочка длиной в восемь базовых оснований оказывается избыточной для кодирования всего четырех городов.

Таблица 1. ДНК-коды городов
Отметим, что для каждого ДНК-кода города, который определяет одинарную ДНК-цепочку, существует и комплементарная цепочка, то есть комплементарный ДНК-код города, причем и ДНК-код города, и комплементраный код абсолютно равноправны.
Далее с помощью одинарных ДНК-цепочек необходимо закодировать все возможные перелеты (Атланта - Бостон, Бостон - Детройт, Чикаго - Детройт и т.д.). Для этого использовался следующий подход. Из названия города отправления брались четыре последних базовых основания, а из названия города прибытия - четыре первых.
К примеру, перелету Атланта - Бостон будет соответствовать следующая последовательность: GCAG TCGG (рис. 11).

Рис. 11. Кодирование перелетов между городами
ДНК-кодирование всех возможных перелетов показано в табл. 2.

Таблица 2. ДНК-коды всех возможных перелетов
Итак, после того как готовы коды городов и возможных перелетов между ними, можно непосредственно переходить к вычислению гамильтонова пути. Процесс вычисления состоит из четырех этапов:
- Сгенерировать все возможные маршруты.
- Отобрать маршруты, которые начинаются в Атланте и заканчиваются Детройтом.
- Выбрать маршруты, длина которых соответствует количеству городов (в нашем случае длина маршрута составляет четыре города).
- Выбрать маршруты, в которых каждый город присутствует только один раз.
Итак, на первом этапе мы должны сгенерировать все возможные маршруты. Напомним, что правильный маршрут соответствует перелетам Атланта - Бостон - Чикаго - Детройт. Этому маршруту соответствует ДНК-молекула GCAG TCGG ACTG GGCT ATGT CCGA.
Для того чтобы сгенерировать все возможные маршруты достаточно поместить в пробирку все необходимые и заранее заготовленные ингредиенты, то есть ДНК-молекулы, соответствующие всем возможным перелетам, и ДНК-молекулы, соответствующие всем городам. Но вместо того, чтобы применять одинарные ДНК-цепочки, соответствующие названиям городов, необходимо использовать комплементарные им ДНК-цепочки, то есть вместо ДНК-цепочки ACTT GCAG, соответствующей Атланте, будем применять комплементарную ДНК-цепочку TGAA CGTC и т.д., поскольку ДНК-код города и комплементраный код абсолютно равноправны.
Далее все эти молекулы (достаточно буквально щепотки, которая будет содержать порядка 1014 различных молекул) помещаем в воду, добавляем лигазов, произносим заклинание и… буквально через несколько секунд получаем все возможные маршруты.
Процесс образования цепочек ДНК, соответствующих различным маршрутам, происходит следующим образом. Рассмотрим, к примеру, цепочку GCAG TCGG, отвечающую за перелет Атланта - Бостон. Вследствие высокой концентрации различных молекул, данная цепочка обязательно встретится с комплементарной ДНК-цепочкой AGCC TGAC, соответствующей Бостону. Поскольку группы TCGG и AGCC комплементарны друг другу, то за счет образования водородных связей эти цепочки сцепятся друг с другом (рис. 12).

Рис. 12. Сцепление цепочек, соответствующих
перелету Атланта - Бостон и Бостону
Теперь образовавшаяся цепочка неминуемо встретится с ДНК-цепочкой ACTG GGCT, соответствующей авиаперелету Бостон - Чикаго, и поскольку группа ACTG (первые четыре основания в этой цепочке) комплементарна группе TGAC (последние четыре основания в комплементарном коде Бостона), то ДНК-цепочка ACTG GGCT присоединится к уже образовавшейся цепочке. Далее к этой цепочке таким же образом присоединится ДНК-цепочка, соответствующая городу Чикаго (комплементарный код), а затем и цепочка авиаперелета Чикаго - Детройт. Процесс образования маршрута показан на рис. 13.

Рис. 13. Процесс образования ДНК-цепочки, соответствующей маршруту
Атланта - Бостон - Чикаго - Детройт
Мы рассмотрели пример образования только одного маршрута (причем это именно гамильтонов маршрут). Аналогичным образом получаются и все остальные возможные маршруты (например, Атланта - Бостон - Атланта - Детройт). Важно, что все маршруты формируются одновременно, то есть параллельно. Причем время, требуемое для создания всех возможных маршрутов в данной задаче и всех маршрутов в задаче с 10 или 20 городами, абсолютно одинаково (лишь бы хватило исходных ДНК-молекул). Собственно, именно в параллельном алгоритме ДНК-вычислений и заключается основное преимущество в сравнении с фон-неймановской архитектурой.
Итак, в пробирке образованы ДНК-молекулы, соответствующие всем возможным маршрутам. Однако это еще не решение задачи - нам необходимо выделить ту единственную ДНК-молекулу, которая отвечает за гамильтонов маршрут. Поэтому на следующем этапе необходимо отобрать молекулы, соответствующие маршрутам, начинающимся в Атланте и заканчивающимся в Детройте.
Для этого используется полимеразная цепная реакция (PCR), в результате которой создается множество копий только тех ДНК-цепочек, которые начинаются с кода Атланты и заканчиваются кодом Детройта.
Для реализации полимеразной цепной реакции применяются два прайма: GCAG и GGCT. Процесс копирования ДНК-модекул, начинающихся с ДНК-кода Атланты и заканчивающихся ДНК-кодом Детройта, показан на рис. 14.

Рис. 14. Процесс копирования ДНК-молекул в ходе PCR-реакции
Отметим, что в присутствии праймов GCAG и GGCT будут копироваться и те ДНК-молекулы, которые начинаются с ДНК-кодов Атланты, но не заканчиваются ДНК-кодом Детройта (под действием прайма GCAG), а также ДНК-молекулы, которые заканчиваются ДНК-кодом Детройта, но не начинаются с ДНК-кода Атланты (под действием прайма GGCT). Понятно, что скорость копирования таких молекул будет гораздо ниже скорости копирования ДНК-молекул, начинающихся с ДНК-кода Атланты и заканчивающихся ДНК-кодом Детройта. Следовательно, после PCR-реакции мы получим преобладающее количество ДНК-молекул в форме регулярной двойной спирали, соответствующих маршрутам, начинающимся в Атланте и заканчивающимся в Детройте.
На следующем этапе необходимо выделить молекулы нужной длины, то есть те, что содержат ДНК-коды ровно четырех городов. Для этого используется гель-электрофорез, что позволяет отсортировать молекулы по длине. В результате мы получаем молекулы нужной длины (ровно четыре города), начинающиеся с кода Атланты и заканчивающиеся кодом Детройта.
Теперь необходимо убедиться, что в отобранных молекулах код каждого города присутствует только один раз. Эта операция реализуется с применением процесса, известного как affinity purification.
Для данной операции используется микроскопический магнитный шарик диаметром порядка одного микрона. К нему притягиваются комлементарные ДНК-коды того или иного города, которые выполняют функцию пробы. К примеру, если требуется проверить, присутствует ли в исследуемой ДНК-цепочке код города Бостона, то необходимо сначала поместить магнитный шарик в пробирку с ДНК-молекулами, соответствующими ДНК-кодам Бостона. В результате мы получим магнитный шарик, облепленный нужными нам пробами. Затем этот шарик помещается в пробирку с исследуемыми ДНК-цепочками - в результате к нему (за счет образования водородных связей между комплементарными группами) притянутся ДНК-цепочки, в которых присутствует комплементарный код Бостона. Далее шарик с отсортированными молекулами вынимается и помещается в новый раствор, из которого затем удаляется (при повышении температуры ДНК-молекулы отваливаются от шарика). Данная процедура (сортировка) повторяется последовательно для каждого города, и в результате мы получаем только те молекулы, в которых содержатся ДНК-коды всех городов, а значит, и маршруты, соответствующие гамильтонову пути. Фактически задача решена - осталось лишь просчитать ответ.
Заключение
Эдлман продемонстрировал решение задачи поиска гамильтонова пути на примере всего семи городов и потратил на это семь дней. Это был первый эксперимент, продемонстрировавший возможности ДНК-вычислений. Фактически Эдлман доказал, что, пользуясь вычислениями на ДНК, можно эффективно решать задачи переборного характера, и обозначил технику, которая в дальнейшем послужила основой для создания модели параллельной фильтрации.
Впрочем, многие исследователи не испытывают оптимизма по поводу будущего биологических компьютеров. Вот лишь маленький пример. Если бы подобным методом понадобилось найти гамильтонов путь в графе, состоящем из 200 вершин, потребовалось бы количество ДНК-молекул, сопоставимое по весу со всей нашей планетой! Это принципиальное ограничение, конечно же, является своего рода тупиковой ситуацией. Поэтому многие исследовательские лаборатории (например, компания IBM) предпочли сфокусировать свое внимание на других идеях альтернативных компьютеров, таких как углеродные нанотрубки и квантовые компьютеры.
После эксперимента Эдлмана было проведено множество других исследований возможностей ДНК-вычислений. Например, можно вспомнить опыт Э.Шапиро: в нем был реализован конечный автомат, который может находиться в двух состояниях: S0 и S1 - и отвечает на вопрос: четное или нечетное количество символов содержится во входной последовательности символов.
Сегодня ДНК-вычисления - это не более чем перспективные технологии на уровне лабораторных исследований, причем в таком состоянии они будут находиться еще не один год. Фактически на современном этапе развития необходимо ответить на следующий глобальный вопрос: какой класс задач поддается решению при помощи ДНК и можно ли построить общую модель ДНК-вычислений, пригодную как для реализации, так и для использования?
 Образование множественного числа существительных Презентация на тему мн число на английском
Образование множественного числа существительных Презентация на тему мн число на английском Средне-специальное образование: хорошо или плохо?
Средне-специальное образование: хорошо или плохо? Виды звезд в наблюдаемой вселенной Космос звезды вселенная
Виды звезд в наблюдаемой вселенной Космос звезды вселенная